主页 > imtoken钱包华为手机安装不了 > 区块链共识算法总结
区块链共识算法总结

作者| 日月通光统筹编辑| 王小曼制作 | CSDN博客

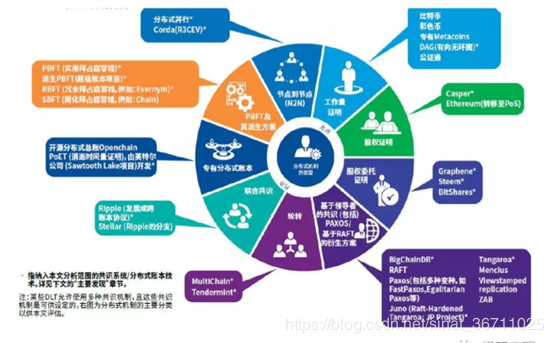
在异步系统中比特币共识算法,需要在主机之间进行状态复制,以确保每个主机都同意状态。 在异步系统中,主机之间可能会发生故障,因此需要在默认的不可靠异步网络中定义容错协议,以保证所有主机达成安全可靠的状态共识。 共识算法实际上是一组选择代表节点的规则和条件。 在车链系统中,公链中有很多这样的过滤方案,如POW、POS、DPOS等,如果没有授权链或私有币系统链,节点的绝对信任、高效的需求链算法无法实现提供公共共识,对于这样的汽车链比特币共识算法,成为首选的共识算法,传统共识,如PBFT PAXOS,Raft等。

拜占庭容错技术是分布式计算中的一种容错技术。 拜占庭假设是由于硬件错误、网络拥塞或中断以及恶意攻击,计算机和网络的行为不可预测。 Byzantine Fault Tolerance就是用来处理这种异常行为并且满足规范的,要处理的。 拜占庭容错系统是一个有 n 个节点的系统。 对于每一个请求,整个系统满足以下条件: 1)所有非拜占庭节点使用相同的输入信息产生相同的结果; 2)如果输入信息正确,所有非拜占庭节点都必须接收到信息并计算出相应的结果。 拜占庭系统中常用的假设有: 1)拜占庭节点可以任意行为,拜占庭节点可以相互串通; 2)节点之间的错误是无关紧要的; 3)节点通过异步网络连接,网络中的网络消息可能会丢失、乱序或迟到。 然而,大多数协议都假定消息可以在有限的时间内传送到目的地。 4) 第三方可以嗅出服务器之间传输的信息,但不能篡改、伪造信息内容或验证信息的完整性。 拜占庭容错由于其理论上的可行性并不实用,并且还需要额外的时钟同步机制的支持。 算法的复杂度随着节点数量的增加呈指数增长。

实用的拜占庭容错算法将拜占庭协议的运算复杂度从指数级降低到多项式级。 PBFT 是一种状态机复制算法,其中服务被建模为状态机,副本复制到分布式系统的不同节点上。 PBFT 需要联邦维护一个状态。 您需要运行三个基本协议,包括共识协议、检查点协议和视图替换协议。 共识协议。 共识协议至少包括几个阶段:请求、预准备和回复。 可能包括准备、提交等阶段。在PBFT通信模式中,每个客户端的请求都要经历五个阶段。 由于客户端无法从服务端获取任何关于服务端运行状态的信息,服务端只能监控PBFT中的主节点是否有错误。 如果服务器在一定时间内不能满足客户端的请求,就会触发视图更改协议。 整个协议的基本流程如下: 1)客户端发送请求激活主节点的服务运行。 2)主节点收到请求后,启动三级协议,将请求广播给各个从节点。 [2.1] 在序号分配阶段,主节点为请求分配序号n,广播序号分配消息和客户端请求消息m,并构造预准备消息给各个从节点。 [2.2]交互阶段,从节点接收到预准备消息,并将准备消息广播给其他服务节点; [2.3] 序号确认阶段,各节点在视图中验证请求和顺序后,广播提交消息,执行从节点 客户端接收请求,向客户端发送响应。 3) 客户端等待来自不同节点的响应。 如果有 m+1 个相同的响应,则响应是操作的结果。

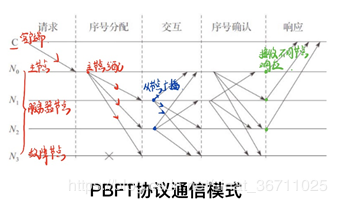
PBFT 一般适用于对一致性要求较高的私链和附属链。 例如,在 IBM 主导的区块链超级账本项目中,PBFT 是一种可选的共识协议。 在Hyperledger Fabric项目中,共识模块被设计为可插拔模块,支持PBFT、Raft等共识算法。

在一些分布式场景下,PAXOS 假设它不需要考虑复杂的故障,而只需要考虑一般的崩溃故障。 在这种情况下,像 PAXOS 这样的协议会更有效率。 PAXOS是一种基于消息传递的高容错共识算法。 PAXOS一共有三种角色:proposer、receiver和learner,主要是proposer和receiver之间的交互。 提议者向网络中超过一半的接受者发送准备消息。 b) 申请人在有足够的acceptors时发送acceptor消息接受者,接受者,接受者,接受者,接受者,接受者,接受者
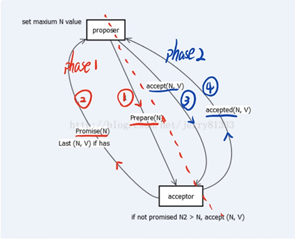
流程图如下图所示:
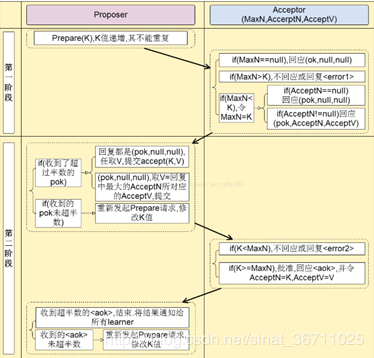
微信PaxosStore中使用了PAXOS协议,以每分钟十亿单的速度调用PAXOS协议流程。

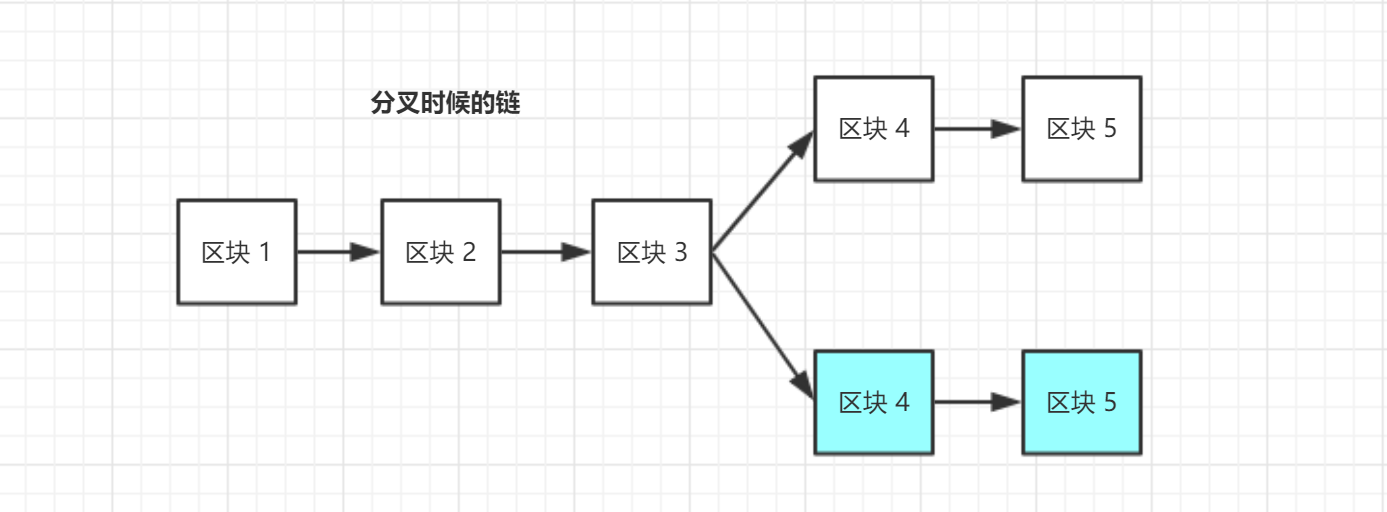
RaftPAXOS 是 Lamport 设计的一种维护分布式系统一致性的协议。 但由于 PAXOS 非常复杂且难以理解,因此出现了各种实现和变体。 Raft是斯坦福提出的一种更易于理解的共识算法,旨在取代广泛使用的PAXOS算法。 Raft 最初是一种管理复制日志的共识算法,是一种针对非拜占庭故障的强共识协议。 Raft 的共识执行过程如下: 首先,选举出一个领导者。 领导者接收客户记账请求,完成记账操作,生成区块,复制到其他记账节点。 领导拥有完整的管理权和核算权。 例如,领导者可以在不考虑其他记账节点的情况下决定是否接受新的交易记录。 领导者可能会失败或与其他节点失去联系。 在 Raft 中,每个节点都处于以下三种状态之一: (1) follower:所有节点开始时都是 follower。 如果没有收到 leader 消息,则成为候选状态。 (2) 候选节点:到其他节点; 选票在; 如果他们获得大部分选票,他们将成为领导者。 这个过程称为领导人选举; (3) leader:系统的所有变更必须先经过leader。 为每个更改写入一个日志条目。 Leader收到变更请求流程如下: 这个过程称为日志复制(log replication) 1) 2) 大部分日志复制给所有follower 节点响应并通知所有follower提交日志 3) 节点日志提交 4 ) 所有follower同时提交日志 5) 现在整个系统的统一raft主要分为两个阶段,首先是leader选举过程,然后在此基础上进行选出的leader的正常操作,比如日志复制,计费等 (1) Leader Election 当一个follower在选举时间内没有收到leader的任何消息时,这个follower将转为candidate状态。
在Raft系统中: 1)任何一个server都可以成为候选者,只要它向其他server的follower发出请求让其选择自己。 2) 如果其他服务器同意,则发出 OK。 如果过程中有追随者倒下,没有收到选举请求,则候选人可以自己选择。 只要获得 N/2+1 的多数票,候选人仍然可以成为领跑者。 3)这样,候选人就成为了领导者,他可以对选民,也就是追随者下达指令,比如记账。 4) 以后会通过心跳消息进行计费通知。 5)一旦领导者倒台,其中一名追随者将成为候选人,并发出竞选邀请。 6) 得到follower的认可,成为leader,继续负责记账等指导工作。 (2) 日志复制和计费步骤如下: 1) 假设leader已经选好,客户端发送添加日志的请求; 2)leader要求follower按照自己的指示在相应的log中添加新的log内容; 3) 大多数follower服务器将交易记录写入账本后,确认添加成功并发送确认消息; 4)在下一个心跳消息中,leader会通知所有follower更新确认项目。 对每个新事务重复此过程。 在此过程中,如果出现网络通信故障,leader无法访问大部分follower,则leader只能更新自己正常访问的follower服务器。
因为服务器的大部分follower都没有leader,所以他们会重新选举一个候选人作为他们的leader,然后由leader作为代表与外界打交道。 如果外界要求增加新的交易记录,新的leader会按照上述步骤通知大部分follower。 当网络通信恢复时,原来的leader会变成follower。 在失去联系阶段,无法确认来自旧领导者的更新,必须回滚以接收来自新领导者的新更新。
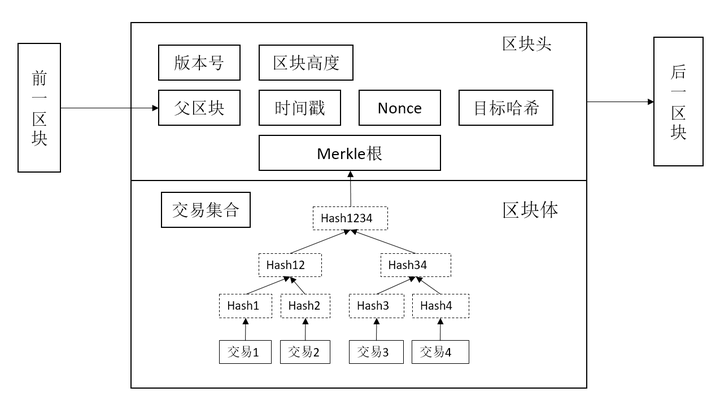

Proof of Workload (POW) 在去中心化的记账系统中,每个加入系统的节点都需要保存一本完整的记账本,但是每个节点不能同时保存记账本,因为节点处于不同的环境,接收的信息不同。 如果他们同时记帐,帐目将不匹配。 通过同时确定哪个节点有权发行票证。 在比特币系统中,每隔10分钟左右就会进行一次权力斗争,获胜的一方有权保留账户并将新的账户信息同步到其他节点。 PoW 系统的主要特点是计算的不对称性。 worker 需要做一些困难的工作才能得到结果,但验证者可以很容易地检查 worker 是否做了相应的工作。 此工作负载的要求是将字符串与名为 nonce 的整数值字符串连接起来,对连接后的字符串执行 SHA256 哈希运算,并验证生成的哈希(十六进制形式)是否以多个零开头。 如果比特币网络中的任何一个节点想要生成一个新的区块并将其写入区块链,就必须解决比特币网络带来的 PoW 问题。 三个关键要素是工作量证明功能、区块和难度值。 工作量证明函数是问题的计算方式,区块决定了问题的输入数据,难度值决定了问题需要的计算量。 (1) 工作量证明功能:SHA256 比特币区块由区块头和区块中包含的交易列表组成。 区块头是一个固定长度的 80 字节输入字符串,用于证明比特币的工作量。

(2) 难度调整在每个全节点独立自动进行。 对于2016年的每个区块,所有节点都会根据统一的公式自动调整难度。 如果块的生成速度大于 10 分钟,则变得更加困难; 如果它以低于 10 分钟的速度生成,它就会变得不那么困难。 公式可以概括为:新难度值=旧难度值的次数; (过去2016个区块所需的时间/20160分钟)工作量证明需要有一个目标值。 硬币的工作证明了目标(goal)公式:目标值=最大目标/最大目标对于一个恒定的难度值:0x000000000x00000000ffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffff与目标值的大小和难度成反比。 在比特币工作量证明中,矿工计算的区块哈希值必须小于目标值。 (3)POW可以解决拜占庭通用币的这个问题 POW共识算法是一种概率拜占庭协议(probability),当不诚实的劳动力少于网管的50%,挖矿难度高(约10分钟/ block) 一个硬币网络达成共识的概念将随着确认的区块类数量的增加呈指数级增长。 但是当不诚实的规模很大,甚至没有接近 50% 时,比特币的共识算法并不能保证正确性,即不保证大部分区块都会由诚实节点提供。 比特币的共识算法不适用于私有链和关联链。 第一个原因是它是最终共识算法,而不是强共识算法。 第二个原因是共识是低效的。扩展知识:一致性
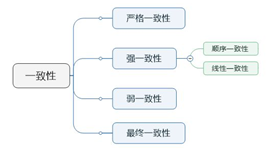
当系统不发生故障并且所有节点在任何时候都不需要通信时,就实现了严格的一致性。 整个系统现在相当于一台机器。 实际上,这是不可能实现的。 强一致性,当分布式系统中的一个更新操作完成后,任意数量的进程或线程都会访问系统获取最新值。 弱一致性是指系统不保证后续的进程或线程访问会返回最近更新的值。 系统不承诺数据写入成功后立即读取最新写入的值,也不承诺数据何时读取。 但是,它会尝试确保它在一定时间后(第二级)。 您可以使数据处于一致状态。 最终一致性是弱一致性的一种特殊形式。 系统保证最后一次更新操作的值最终会被返回,不需要后续更新。 换句话说,如果更新后的数据需要在一段时间后可以访问,那就是最终一致性。
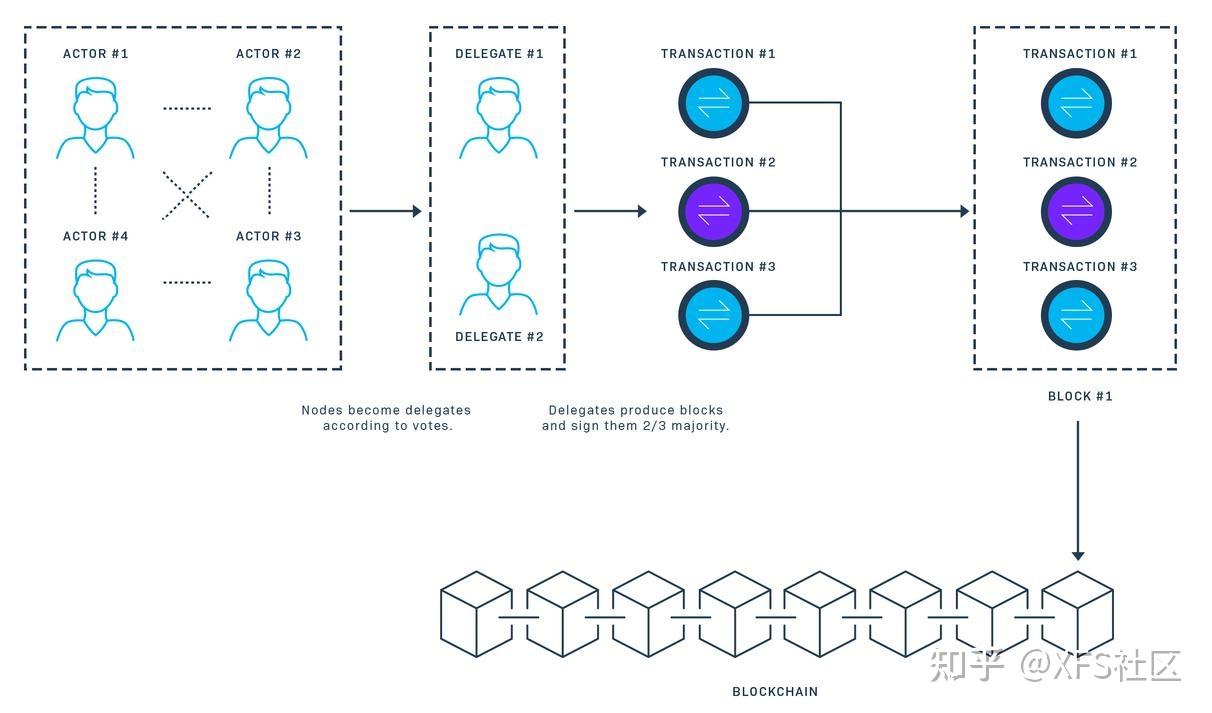

在权益凭证的POS模式中,有一个名词叫货币时代。 每种货币每天都有一个货币年龄。 比如你持有100个币一共30天,那么你的币龄就是3000。你每取出365个币,你将从区块中获得0.05个币的利息(假设利率可以理解为5%每年),所以在这种情况下,利息 = 3000 * 5% / 365 = 0.41 个硬币,这很有趣。 Peel 是第一个采用公平证明的货币。 peERCoin 的公平证明机制结合了随机化和币龄的概念。 至少 30 天未使用的币可以参与下一个区块。 更长更大的硬币组更有可能签署下一个区块。 一旦该币种的利息被用于签署一个区块,币龄将被清零,您必须等待至少 30 天才能签署另一个区块。 虽然 POS 机制考虑到了 POW 的缺失,但基于利益平衡的选择会导致最富有的人的账户拥有更大的权力,可能支配记账权。 授权共享机制(authorization to obtain certificates,DPOS)的出现正是基于解决这一不足的POW和POS机制。

Bitshare 是一种使用 DPOS 机制的加密货币。 这个想法是,每个持有 bit 股份的人都有投票权来产生 101 个代表,我们可以将其视为 101 个超级节点或池,它们彼此拥有完全相同的权利。 如果代表未能履行他们的职责(并且在轮到他们时未能产生区块),他们将被移除并且网络选出一个新的超级节点来取代他们。 Bitstocks 引入了 witness 的概念,witness 可以产生区块,每个拥有 Bitstocks 的人都可以投票给 witness。 前 N 名候选人(N 通常定义为 101)的同意票可以被选为见证人,被选为见证人的人数(N)必须至少有一半的参与选民认为 N 已经充分去中心化变化。 每个维护周期(1 天)都会更新候选见证人列表。 然后见证人被随机化,每个见证人有 2 秒的许可时间按顺序生成区块。 如果见证人无法在给定的时间片内生成区块,则将出块权限授予下一个时间片对应的见证人。 比特币设计了另一种活动——代表竞赛。 Elected representatives have the power to propose changes to network parameters, including transaction costs, block sizes, witness fees, and block intervals. 如果大多数代表同意拟议的变更,股东有两周的审查期,在此期间他们可以召回代表并废除拟议的变更。 这种设计确保代表在技术上没有直接修改参数的权利,并且所有对网络参数的修改最终都需要股东批准。

瑞波币(RippleRipple)是一种基于互联网的开源支付协议。 在 Ripple 网络中,交易由客户端(应用程序)发起,交易通过跟踪节点或验证节点广播到全网。 跟踪节点的主要功能是分发交易信息和响应客户分类帐请求。 除了包含跟踪节点的所有功能外,验证节点还可以通过共识协议将新的账本实例数据添加到账本中。

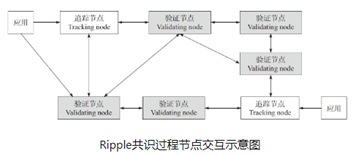
波纹共识在验证节点之间产生,每个验证节点都预先配置了一个称为 UNL(唯一节点列表)的受信任节点列表。 列表中的节点可以对事务的完成进行投票。 每隔几秒,Ripple 网络将遵循以下共识流程: 1)每个验证节点将继续从网络接收交易。 与本地账本数据核对后,直接丢弃非法交易,将合法交易归纳为候选集。 交易候选集还包括共识过程确认失败后剩余的交易。 2) 每个验证者将自己的一组交易候选者作为提案发送给其他验证者。 3)验证节点收到其他节点的提案后,如果不是来自UNL上的节点,则忽略该提案; 如果来自 UNL 上的某个节点,则提议的交易将与本地交易候选集进行比较,如果相同,则该交易获得一票。 当协议在规定时间内获得超过 50% 的选票时,进入下一轮投票。 不超过 50% 的交易将在下一次共识过程中得到确认。 4) 验证节点将获得50%以上票数的交易作为提案发送给其他节点,同时将所需票数的门槛提高到60%。 重复步骤 3) 和 4),直到阈值达到 80%。 5)验证节点正式将80%的UNL节点确认的交易写入本地账本数据,称为last closed ledger,即账本的最后(最近)状态。
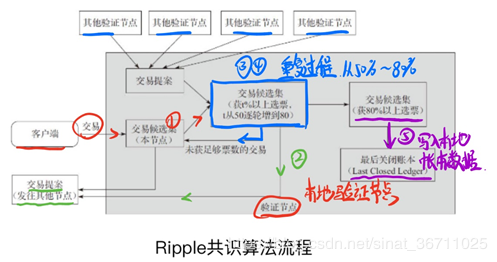
在 Ripple 的共识算法中,投票节点的身份是预先知道的。 该共识算法仅适用于权限链场景。 Ripple共识算法的拜占庭容错(BFT)能力为(n-1)/5,这意味着它可以在不影响正确共识的情况下容忍全网20%节点的拜占庭错误。 在区块链网络中,由于应用场景不同,设计目标也不同,不同的区块链系统采用不同的共识算法。 一般来说,在私有链和联盟链的情况下,对一致性和正确性有很强的要求。 一般来说,应该使用一致性强的共识算法。 在公案链中,一致性和正确性通常不可能做到 100%,通常采用最终一致性(final Consistency)共识算法。 共识算法的选择与应用场景高度相关。 可信环境使用paxos或raft,授权联盟可以使用PBFT,非授权链可以使用pow、pos、ripple共识等,共识机制可以根据对方之间的信任程度自由选择。
版权声明:本文为CSDN博客《日月》原创文章。 遵循CC 4.0 by-sa的版权协议。 转载请附上原稿和本声明链接。
原文链接: